
Alice's Complicated Family
In which various LLMs compete to see who can solve a set of very easy riddles, based on the exceptionally complex and ever-shifting family relationships of a woman named Alice

Saw this thread on Twitter discussing various claims made about ChatGPT-4o and whether it’s lived up to the hype. Haven’t gotten through it, more on that later, but this caught my eye:

I copied it over into four different models that I had handy on my phone: ChatGPT (running 4o), Claude 3.5 Sonnet, Gemini 1.5 Pro Experimental 0827, and Llama 3.2 3b Instruct q4 (loaded on my iPhone 16 Pro using the Pocket Pal app)1. My methodology was to just say “try again” if it didn’t get it right on the first shot and see how long it took to return the correct answer.
For the first riddle, Variation 2 in the illustration above, here are the results:
ChatGPT-4o — wrong answer (2) on first, got it on second
Claude 3.5 Sonnet — wrong answer (2) on first, got it on second
Gemini 1.5 Pro Exp — correct on first try
Llama 3.2 3b — Amazingly bad. The first response was that it could not answer given the information stated because nothing was indicated about Alice’s brother’s siblings. I told it to try again, same response. I then said “her brothers are related to her sisters” and it responded that her brothers have two sisters. Same wrong answer as the other models, so I said “wrong answer, try again” and it said 2 again. This went on for three more turns until I said expressly “try again and the answer is not two.” And it answered … two. Insert face palm emoji.
For the second riddle, same methodology:
ChatGPT-4o — wrong answer (1) on first, got it on second
Claude 3.5 Sonnet — correct on first try
Gemini 1.5 Pro Exp — wrong answer (1) on first, got it on second
Llama 3.2 3b — Amazingly bad. First answer was wrong (1) and then it went to zero, and kept answering that. I told it the answer was neither zero nor one and to try again and it said … one. More face palm.
The tweet author, Jenia Jitsev, sets up a test on these sorts of problems and benchmarks the 4o model against 4o-mini and find that the 4o model needs approximately 1 try to get the right answer, while the 4o-mini model is all over the place.
He then tests against the extended problem sets, similar word problems that require you to know that, e.g., an uncle is the sibling of your parent and your uncle’s niece is your sister if your parent only has one sibling. These aren’t hard, requires a couple of extra steps, my eleven year old son got the answers correct while watching YouTube on his phone almost as soon as I read the problem out to him. He finds, however, that even the 4o model has substantial variation of answers.
Both models purportedly ace the Math Olympiad and International Olympiad of Informatics problems, problems that are way harder than these. Moreover, there shouldn’t be any variation at all, he argues, because the reasoning required is the same: you either get it or you don’t, so maybe plus or minus one prompt is within variation, but not 6+. Jitsev speculates that maybe the MO and IOI problems leaked into the training data and thus it’s just not reasoning at all.
One response by Lucas Beyer:
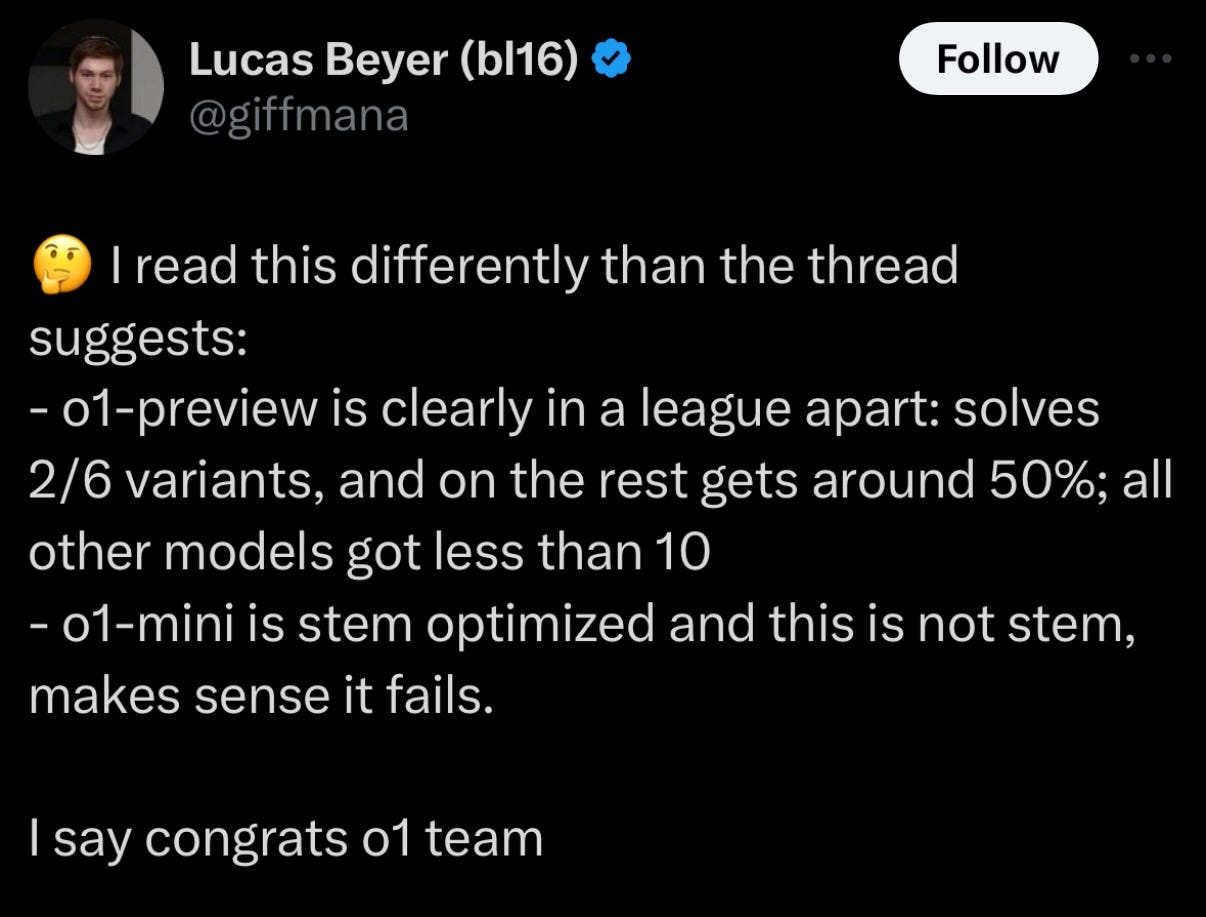
Once again I marvel at the sublime, nay poetic, artistic facility that the nerds at AI labs have for naming their models. No notes, 10/10. One can only wonder what their cats are named, or God forbid their children.